このブログは、大規模言語モデル(LLM)の技術的なポイントを整理した記事です。事前学習や評価など、それぞれのポイントにおいて参考になる文献・資料・動画もリストアップしています。
Introduction
LLMは、東工大岡崎先生の2024年度 人工知能学会全国大会(第38回)チュートリアル講演1の中の定義を引用すると、「大量の計算と膨大な言語データで学習した多数のパラメータを持つ言語モデル」です。どれだけ大規模かというと、例えば2024/7/23にMetaよりLLama3.1が発表されましたが、モデルのパラメータ数は大きいもので405B (4050億)にものぼり、使用したトークン数は15T+、計算量はH100-80GB上で合計39.3M GPU 時間にものぼります。
* トークンとは、テキストを処理する際の最小単位です。”learning”や”re”などの単語または単語の一部などを表します
大量の計算と大規模な言語データによる学習により、2022年以降のLLMは、いくつかのタスクに対して人よりも高い性能を次々に実現してきました。そのLLMの基礎となる技術を見ていきましょう。以下は、LLMの歴史を示していますが、まずは言語モデルのアーキテクチャの発展からみていきます。
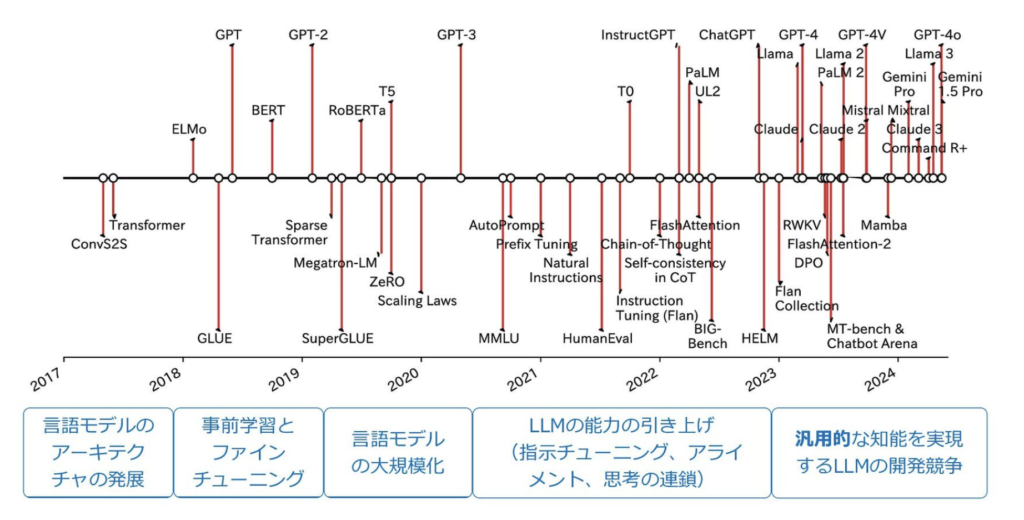
言語モデルのアーキテクチャの発展(Transformer)
従来の自然言語処理 (RNN / LSTMなど)
自然言語処理の分野では、SVMやCRFなどの統計的機械学習に基づいた解析手法から、word2vecやRNN(Recurrent neural network)、LSTM(Long short-term memory)などに代表されるニューラル・ネットワークへ流れが移っていきました。RNNやLSTMは原理上過去に登場した単語を記憶することができるように設計をされていますが、長期の記憶を表現し切れないという問題がありました。例えば、seq2seqモデル(英語を入力して日本語を予測するようなモデル)を機械翻訳に適用した場合、decoder(モデルの出力部分)は「固定長のベクトル」のみに基づいて、対訳文を生成しなければならず、encoder(モデルの入力部分)は入力に含まれる情報全てを「固定長のベクトル」に押し込めなければいけないのですが、固定長のベクトルに押し込める情報には限りがあるので、入力文が長いほど精度が低下するという問題がありました。
Attention(注意機構)の登場
そこで、各単語の情報を固定長のベクトルに情報を全て押し込めるのではなく、decoder(モデルの出力部分)が入力文の各単語の情報を直接利用する構成にするアーキテクチャが試されてきました。つまり、RNNやLSTMでは入力単語すべてを1つの情報に圧縮して使っていたのに対し、それに追加して入力の単語自体もそれぞれ情報として使用するという発想です。発想としてはシンプルですが、入力の単語自体を全て入力すると無駄に情報量が多くなり、うまく学習できないという難しさがありました。そこで、Attention(注意機構)(Bahdanau et al., 2014)の登場です。単純に直接各単語をすべて利用するのではなく、どのトークンに注目をするべきかを重みづけするというアイデアが、この問題を解決し、長い入力の翻訳精度を向上させました。ちなみに2016/11時点でのGoogleニューラル機械翻訳はLSTMとattention機構で構成されていました。

Transformerの登場
しかしながら、Attentionだけでは、入力文中の単語間、出力文中の単語間の長距離依存(人間でいうところの文脈の理解といったところでしょうか)を考慮しづらいという問題がありました。そのブレークスルーとなったのが、Transformer (Vaswani et al., 2017)です(TransformerはTitleがAttention Is All You Needというキャッチーなところも話題になりました。)。TrasnfrormerはSelf-Attentionという概念を使用しています。下図はSelf-Attentionの概略図です。単語の(固定)トークンを使う代わりに、系列全体の情報を使って文脈を把握するような単語(tokenといいます)の埋め込み(embedding)をまず行います。こうすることで、Appleが果物としてのAppleなのか、会社としてのAppleなのか、文脈を捉えた表現がしやすくなります。
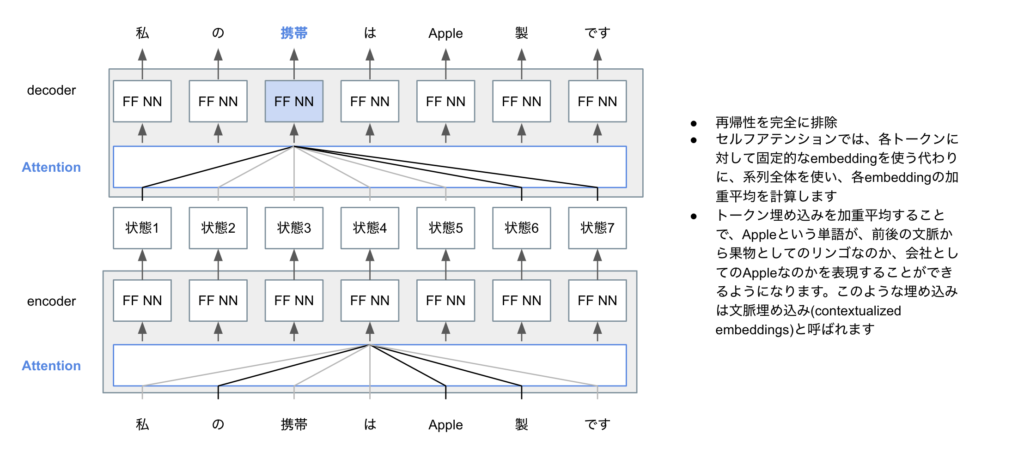
また、位置エンコーディング(その単語がどこの位置にあるのかを表す情報)やマルチヘッドなどの工夫を盛り込みことで、長距離依存を扱いやすくしたのもTransformerの画期的なポイントです。下記の図は、元論文で掲載されているTransformerの図に、解説を追加したものです。

より詳しくTrasnformerを知りたい方は、下記などの解説から概要を掴んで、元論文にチャレンジしてみると良いかもしれません。
- わかりやすい解説記事(英語)(MITでも読まれているらしい) https://jalammar.github.io/illustrated-transformer/
- わかりやすい解説記事(上記を日本語訳したもの) https://tips-memo.com/translation-jayalmmar-transformer
また、Transformerの重要な特徴として、構造上並列計算で実装を行いやすいという特徴があります。Transformerの並列計算の容易さが大規模な計算を可能にし、昨今のLLMの進展につながってきました。なお、大規模計算については、東京工業大学横田理央先生にW&BのMeetupで解説いただいたのですが、その動画(「大規模言語モデル開発を支える分散学習技術」)が公開されています。関心がある方はご確認ください。
コラム: Attention/Transformer 開発者の話
Weights & BiasesのPodcastで、Weights & Biases CEOのLukasとTransformerの元論文”Attention is All You Need”のauthorの一人であるAidan Gomezの対談が面白いです(Aidan Gomez – Scaling LLMs and Accelerating Adoption)。意訳すると”Transformerは複雑と言われるけれども、LSTMsやRNNsなどの系譜を考えれば、シンプルな拡張であると考えている。一方、今までのやり方と反したことは、皆が巨大なモデルを最初から作りたがらない中、思い切って巨大なモデルを作ってみたこと。Transformerは巨大モデルの計算を可能にするStructureであり、これが功を奏した”と言うのが彼のコメントです。「Transformerなんてよく思いついたな」と考えていた私にとって、何が彼らにとって過去の知見に基づいたことなのか/何が斬新なことだったのかというポイントが面白かったです。
LLM開発のステップ
モデルのアーキテクチャの進展について解説をしましたが、次は、LLM開発のステップを解説していきます。以下は、LLMの開発からLLMを用いたアプリケーション開発までの流れを示していますが、このブログでは評価のところまでを解説していきます。OpenAIのAPIなどを利用する場合はすでに学習されたモデルを使うことになるので、LLMの開発に触れることはありませんが、LLMの開発を理解することで、考え得るLLMのユースケースの幅が広がるので、一つずつ見ていきましょう。

事前学習
まずは事前学習です。事前学習は、大規模なコーパスを用いて学習し、コーパスの中の知識を獲得した基盤モデルを作る過程です。学習は、Trasnformerのところで解説をしたように、穴抜けの(もしくは次の)トークンを予測する形で行われます。事前学習については、日本のLLM領域で知らない人はいないSanaka.aiの秋葉さん、CyberAgentの石上さん、東工大の藤井さんの動画やブログが参考になります。
- LLMの開発は難しい?簡単?Stability AIの現場から – Stability AI 秋葉さん @ W&B Fully Connected Tokyo
- CyberAgentにおける日本語LLMの開発について CyberAgent石上様
- GENIAC: 172B 事前学習知見 (東京工業大学の藤井さん)
事前学習は大量の計算資源と高度な専門知識が求められるので、全てのプレイヤーが参画できる領域ではないのですが、事前学習を行なった後の多くの基盤モデルが、HuggingFaceで公開されています。OpenAIなどのapiなどを使わない場合であっても、事前学習を自社で一から行う必要はなく、公開されているモデル(オープンウェイトなモデルともいいます)をダウンロードして利用することができます。
継続事前学習
公開されている基盤モデルは、モデルを活用していきたい特定のドメインの知識を獲得していないことが多く、事前学習を行なったモデルに対して、知識を追加する過程が求められることがあります。それを実現するのが、継続事前学習です。継続事前学習は、事前学習のように穴抜けの(もしくは次の)トークンを予測する形で学習が行われますが、独自のコーパスを入れることで新しい知識を獲得することができます。継続事前学習については、東工大の藤井さんのブログが実践的でわかりやすいです。以下のブログでは、MetaのLlama3に対して日本語のドメインを追加で学習したSwallowの開発過程を解説しています。
なお、公開されているモデルは、そもそも既存のモデルアーキテクチャを使用したり、ある基盤モデルから継続事前学習をしたモデルであることが多いです。日本語のLLMの系統図については、私も執筆している「大規模言語モデル(LLM)評価のベストプラクティス」の図がわかりやすいかと思います。以下の図は、どのモデルがどのアーキテクチャを踏襲しているかが記載されています。
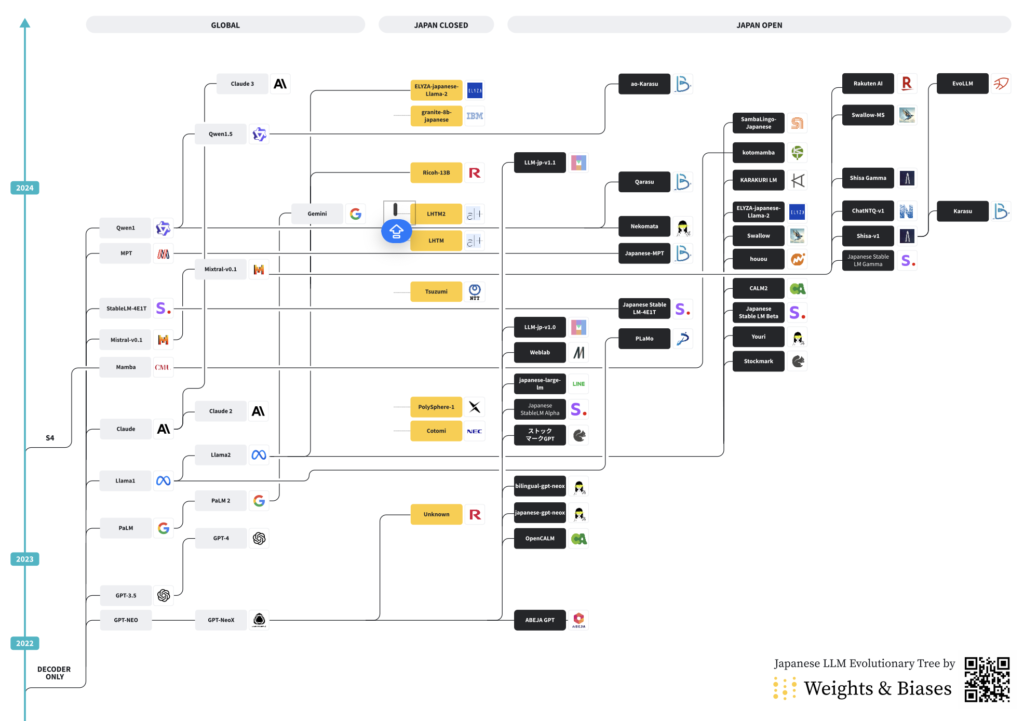
ファインチューニング
事前学習後の基盤モデルは、それ自体では次のトークンを予測するモデルであるので、タスクに対して、適切なフォーマットで回答をしてくれるモデルにはなっていません。ファインチューニングは、モデルがタスクのフォーマットに従うことを目的とし、タスクに特化した教師ありデータ(入力と出力のペア(厳密には一つのテキストに合体されている))で学習を行う方法です。ファインチューニングまでなってくると、必要とされる計算リソースは比較的少ないため、技術的・リソース的参入障壁がグッと下がってきます。
また、一つのタスクではなく、様々な指示文に対して、理想的な出力文を正解とする教師あり学習を行うことで、未知のタスクに対してのZero-shot性能を上げることができるインストラクション・チューニングという方法があり、このインストラクションチューニングが、LLMを使いやすいものにしてきました。

ファインチューニングは知識獲得できる?
ファインチューニングによって知識獲得できるかという議論が度々起こりますが、ファインチューニングによって知識を獲得することはないことが報告されています。
- Zhou, Chanting, et al. (2023) : ファインチューニングは事前学習で獲得された知識・能力を引き出すことで性能を改善しているだけ
- Kung and Peng (2023): Instruction Tuningによる性能改善は、タスクの理解を通じてではなく、出力形式といった表面的事項の学習に起因する
Prompt Engineering
上記のLLMの開発過程のフローには入っていないですが、プロンプトエンジニアリングもLLMを語る上で重要な技術なので、触れておきます。
アーキテクチャの工夫に加え、言語モデルに学習させる文章(prompt)の工夫もその進化を進めてきました。対話という新しいインターフェースのもと、入力の工夫・段階的な推論により大幅な精度向上が実現されたという点も、LLMが注目を集める要因であると考えられています。Promptは、機械に与える呪文のようなもので、呪文の投げかけ方により、モデルの精度が変わってきます。Promptはモデルが学習している内容自体を大きく変えることはしないのですが、答えるstyleを提示してあげることで、モデルが持つpotentialを引き出すような手法です。
うまくいくPromptが次々に解明されつつあり、基本的に細かく適切に指示をするほど回答の質が高いことが知られているのですが、Promptで詳細に記載する内容に応じてレベル分けをする論文も出されるほどです。
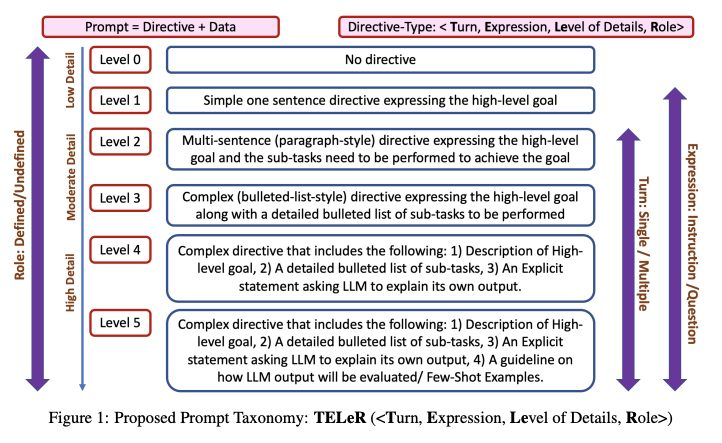
その中でもいくつかうまくいくと考えられているPromptのコツを下記で紹介します。
- Few-shot prompting
- Chain-of-Thought Prompting
- Tree-of-Thought Prompting
- Active-Prompt
- Directional Stimulus Prompting
- ReAct Promptin
- Self-Refrection
- Self-Consistency
- Generate Knowledge Prompting
- Automatic Prompt Engineering
- Multimodal CoT Prompting
- Graph Prompting
例えば、Few-shot Learningというのは、問いに対する回答例をいくつか提示し、回答形式や振る舞いを事前に学ばせる手法です。事前に回答の形式を与えることで、回答の精度があがることが知られています。
Chain of Thought(思考の連鎖)は、いきなり回答を求めるのではなく、段階的に答えを出すようにするPromptの手法で、これによって精度が上がるということが知られています。Promptの中で”段階的に考えてください”と打つだけでも効果があることが私も経験的に多いです。

Self-Reflectionは、言語モデルが生成した文章を言語モデルに再考させる手法です。生成モデルは、確率的に次にくる単語を予測して出力しているだけになるので、過去に自身が生成した文章を基本的には修正をしません。そのため、一度生成した回答を再度確認させるような指示を与えるだけで回答の質が上がることが知られています。例えば、”to be sure that we have the right answer (筋の良い答えを得ていることを確認してね)”と打ち込むだけでも効果があります。
余談ですが、水曜日のダウンタウンで、街行く人に「いいえ私は蠍座の女」と答えさせるまで帰れないという企画がありました。ロケの最初は、普通に星座を聞いていたのですが、シンプルに「いて座です」という回答しか返ってきませんでした。ロケの後半では、芸人が学習をして、テンプレートを作り始めました。コンビ間で、「あなたはいて座の男ですか?」⇒「いいえ、私は天秤座の男」ですという流れを作った後に、「あなたはいて座の女ですか?」という質問を投げかけることで、「いいえ、私はOO座の女」という返してくれるテンプレートを作ったのです。あとは蠍座の女性を探すだけですね。面白いPrompt Engineeringです。
アラインメント
チャットボットのようなアプリケーションを作る場合、実は基盤モデルだけでは、「良いっぽい回答」を得ることが難しく、ChatGPTなどは、さらにもう一手間行っています。それがReinforcement Learning from Human Feedback (RLHF)です。「人間の受け答えとして自然な感じ」と言うのは定量的な評価ができないため、人が採点をしていく過程を学習プロセスに入れ、よりよい答えがでやすいようにするという発想です。
下記の図は、Andrej Karpathy (Open AI co-founder)が”State of GPT | BRK216HFS“の中でも使用しているChatGPTの開発過程を表した図です。強化学習(Reinforcement Learning)に関連するステップは、後半の2つのステップにあたります。

- Pretraining: ここは上記で解説した事前学習です。
- Supervised Finetuning: ここは上記で解説したファインチューニングです。
- Reward Modeling: この段階以降では、回答が「いい感じ」になるようにモデルを微調整していきます。まず、この段階のモデルに対して、いくつかのプロンプトを与え、それぞれのプロントに複数の出力を得ます。複数の出力の中で、人間が「良い」と思う順番をランキングづけし、それらのデータを用いて報酬モデルを学習します。人間の「いい感じ」のメカニズムをここで獲得します。
- Reinforcement Learning: 最後に前段の報酬モデルから得られる報酬(reward)に基づき、Proximal Policy Optimizationというアルゴリズムを用いて、より「いい感じ」の回答が出力されるように強化学習を使ってモデルをfine-tuningしていきます。この最後のステップを入れることで、回答がより「いい感じ」になったとされています。
少し難しいかもしれませんが、人間のフィードバックを強化学習の中に与えながら学習する枠組みが、Reinforcement Learning from Human Feedback (RLHF)です。人間が好ましいと考える結果を反映させる手法として、重要な技術であると考えられています。なお、ChatGPTの開発にあたり、「いい感じの文章を作ってください」というより、「いい感じの文章を選択してください」という方が簡単なタスクになりますが、こうしたデータを取得しやすいやり方が功を奏したと言われています。
評価
学習の後は評価です。タスクに対して所望の精度が出ているかを評価するプロセスは、従来のAI同様に重要になります。一方、従来のAIと異なり、LLMは様々なタスクに適用可能であることや、出力が数字やカテゴリではなく、長いテキストであることも多く、従来のAIと異なり、一層評価が難しくなっています。
私は個人的にLLMについては、この評価に時間を最も費やしてきました。例えば、W&Bでは、日本で最大規模のLLMリーダーボードを開発したり、経産省のGENIACプロジェクトで利用される評価体系の構築も行なってきました。
評価だけでも非常に長くなるのですが、2024年上半期までのLLM評価について体系的に「大規模言語モデルを評価するためのベストプラクティス」というホワイトペーパーにまとめているので、是非ご覧ください。
最後に
このブログでは、LLMに関して解説をしてきました。OpenAIやClaudeのチャットボットは非常に便利で、私も毎日使っていますが、チャットボットというインターフェースによるLLMの活用は、LLMの一つの側面にすぎません。事前学習や継続事前学習による知識獲得やファインチューニングによるタスクへのフォーマット適用を理解することで、ユースケース特化のLLM活用の可能性が広がる考えています。例えば、臨床文書からのエンティティ抽出のために「症状,部位,薬品名,検査名,各種数値などの医療表現を抽出した上で,万病辞書や百薬辞書を用いて病名と薬品名を対応コードに標準化する,訓練済み機械学習モデル」などのモデルやヘルスケア領域に特化したコーパスを提供しているNAIST荒牧先生のソーシャル・コンピューティング研究室の取り組みは非常に興味深い例です。
また、近年の自然言語処理の技術革新は自然言語だけにとどまりません。例えばライフサイエンスの領域では、アミノ酸配列や遺伝子配列の解析にTransformerが用いられ(アミノ酸の配列や遺伝子の配列 = 文字)、薬の開発などに役立てられています(この領域のoverviewとしては、Large Language Models in Molecular Biologyがわかりやすいです)。私個人としては、この領域は力を入れているところで、2024年以降、10社を超える製薬企業にハンズオンを提供したり、W&Bのお客様と実際に使えるワークフローの開発も行なっています。ブログも公開しているのでPart1だけでも、是非ご確認下さい。
OpenAIやClaudeを超えるチャットボット開発は難しくとも、LLMの技術的なポイントを押さえた効くユースケースの開発であれば勝機はあると考えています。
