この記事は、大規模言語モデル(LLM)の概要を理解したい方向けに、1回で読み切れる分量でまとめた日本語記事になっています。よく質問をいただく内容なので、腰をあげてTransformerやPrompt、RLHFといったLLMを理解する上で欠かせない要素をまとめました。なお、Referenceにも記載していますが、この手の内容だと、英語が理解できる方はAndrej Karpathy (Open AI co-founder)の講演”State of GPT | BRK216HFS“が動画でわかりやすい解説かと思いますので是非見てみてください。また、より技術的なLLMの取り扱いは、Weights & BiasesのLLM White Paper “LLMをゼロから トレーニングするためのベストプラクティス”が非常にわかりやすく質の高い資料になっているので、是非ご覧ください。それではLLMの概要を追っていきましょう。
Transformerの登場と基盤モデルとして進化
従来の自然言語処理 (RNN / LSTMなど)
自然言語処理の分野では、SVMやCRFなどの統計的機械学習に基づいた解析手法から、word2vec やRNN(Recurrent neural network)、LSTM(Long short-term memory)などに代表されるニューラル・ネットワークへ流れが移っていきました。RNNやLSTMは原理上過去に登場した単語を記憶することができるように設計をされていますが、長期の記憶を表現し切れないという問題がありました。例えば、seq2seqモデル(英語を入力して日本語を予測するようなモデル)を機械翻訳に適用した場合、decoder(モデルの出力部分)は「固定長のベクトル」のみに基づいて、対訳文を生成しなければならず、encoder(モデルの入力部分)は入力に含まれる情報全てを「固定長のベクトル」に押し込めなければいけないのですが、固定長のベクトルに押し込める情報には限りがあるので、入力文が長いほど精度が低下するという問題がありました。
Attention(注意機構)の登場
そこで、各単語の情報を固定長のベクトルに情報を全て押し込めるのではなく、decoder(モデルの出力部分)が入力文の各単語の情報を直接利用する構成にするアーキテクチャが試されてきました。つまり、RNNやLSTMでは入力単語すべてを1つの情報に圧縮して使っていたのに対し、それに追加して入力の単語自体もそれぞれ情報として使用するという発想です。発想としてはシンプルですが、入力の単語自体を全て乱暴に入力すると無駄に情報量が多くなり、うまく学習できないという難しさがありました。そこで、Attention(注意機構)(Bahdanau et al., 2014)の登場です。単純に直接各単語をすべて利用するのではなく、どのトークンに注目をするべきかを重みづけするというアイデアが、この問題を解決し、長い入力の翻訳精度を向上させました。ちなみに2016/11時点でのGoogleニューラル機械翻訳はLSTMとattention機構で構成されていました。

Transformerの登場
しかしながら、Attentionだけでは、入力文中の単語間、出力文中の単語間の長距離依存(人間でいうところの文脈の理解といったところでしょうか)を考慮しづらいという問題がありました。そのブレークスルーとなったのが、Transformer (Vaswani et al., 2017)です(TransformerはTitleがAttention Is All You Needというキャッチーなところも話題になりました。キャッチーすぎる論文タイトルはいかがなものかと意見もあります)。TrasnfrormerはSelf-Attentionという概念を使用しています。下図はSelf-Attentionの概略図です。単語の(固定)トークンを使う代わりに、系列全体の情報を使って文脈を把握するような単語(tokenといいます)の埋め込み(embedding)をまず行います。こうすることで、Appleが果物としてのAppleなのか、会社としてのAppleなのか、文脈を捉えた表現がしやすくなります。
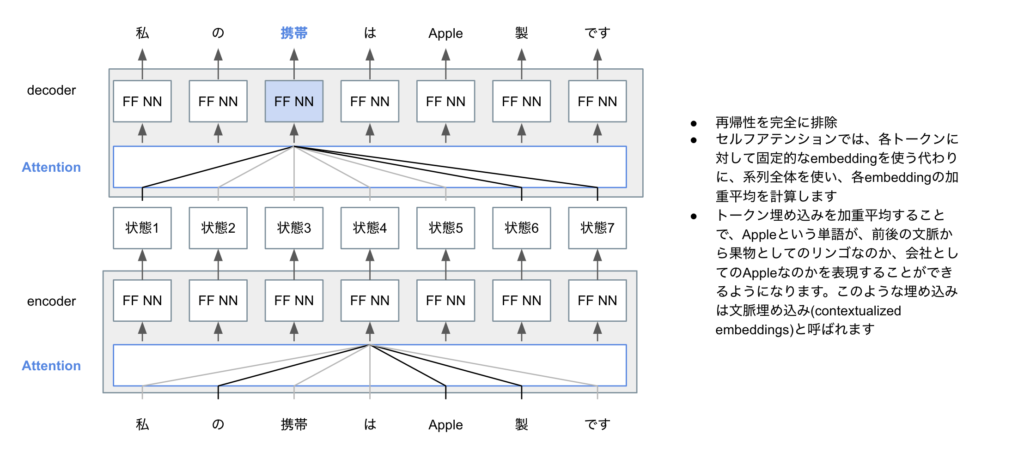
また、位置エンコーディング(その単語がどこの位置にあるのかを表す情報)やマルチヘッドなどの工夫を盛り込みことで、長距離依存を扱いやすくしたのもTransformerの画期的なポイントです。下記の図は、元論文で掲載されているTransformerの図に、解説を追加したものです。
#技術の概要を抑えたい方にとっては難易度が高いかと思いますが、よく出てくる図なので解説
#query・key・valueを説明するとすごく長くなるので省略をしますが、重要な概念ですので深く理解していきたい方はトラックしてみてください
#下記の太陰太極図のような箇所が位置エンコーディングを示しているのですが、これは位置エンコーディングで使われるcosine派を表現しているといわれています。

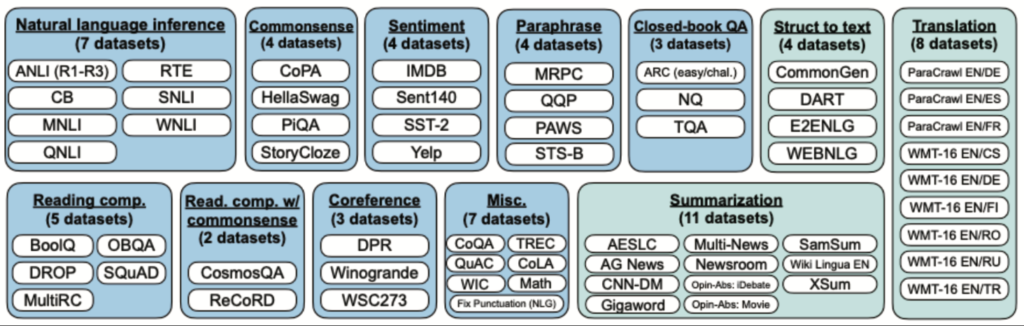
自然言語処理には翻訳や要約、質問応答など、様々なタスクがありますが、それぞれのタスクごとにモデルを作るのではなく、Transformerを用いて1つのアーキテクチャを作り、下流のタスクにファインチューニングするだけで様々なタスクに対応することができるようになってきたことも2021年以降のLLMの進展の大きなポイントです。大規模なデータで訓練され、様々なタスクに適用できる汎用モデルは、基盤モデル(Foundation model)と呼ばれます。現在では、非常に多くのタスクが基盤モデルに基づいて開発がされており、ここ数年のAI分野の進展に大きな影響を与えています。翻訳や要約をはじめとして、LLMの下流タスクとしては下記のようなタスクがあります。様々なタスクに対しての標準的な評価ベンチマークも提案が進んでおり、下記の図にはそれぞれのタスクの代表的な評価ベンチマークとなるデータセットも記載されています(なお、青字がNLUタスク、ティール字がNLGタスクです)。
そして、大規模なモデルは限られた人がアクセスできるものでしたが、HuggingFaceやStability.AI などのOpen Sourceなモデルにより、実際にモデルを容易に開発したり、使ったりすることができる人が増えたことで、大規模言語モデルの発展が一段と進んできました(言語モデルに限らず画像などの生成モデルの開発も同じように進んできました)。より詳しくTrasnformerを知りたい方は、下記などの解説から概要を掴んで、元論文にチャレンジしてみると良いかもしれません。
- わかりやすい解説記事(英語)(MITでも読まれているらしい) https://jalammar.github.io/illustrated-transformer/
- わかりやすい解説記事(上記を日本語訳したもの) https://tips-memo.com/translation-jayalmmar-transformer
Transformerは構造上並列計算で実装を行いやすいという特徴があります。だからこそ大規模なtoken(単語)を学習することができるようになってきたと考えられますが、並列計算をしやすいというのは個人的にもTransformerの非常に重要な要素であると考えています。
Transformer登場後のLLM
OriginalのTransformerはencoderとdecoderのアーキテクチャの2つから構成されていますが、今ではencoderだけのアーキテクチャを進化させたもの(BERTやRoBERTa、DistilBERT、ALBERT、ELETRA、XLMなど)やdecoderだけのアーキテクチャを進化させたもの(GPT系のモデルやCTRLなど)、encoder・decoderを両ブロックを引き続き使ったもの(BARTやT5など)があります。下記が、2023/4に発表されたReview論文の中で掲載されたLLMの系譜です。青色の樹形図がdecoderだけを使用したモデル、緑色の樹形図がencoderとdecoderを両方使用したモデル、そしてピンク色がencodercomだけを使用したモデルです。
ちなみに日本では2023/5/17にサイバーエージェントが最大68億パラメータの日本語LLMを商用利用可能なCC BY-SA 4.0ライセンスでHugging Face上で一般公開し、またrinna株式会社は同日に、36億パラメータの汎用言語モデルと対話言語モデルの2種類の日本語GPT言語モデルをオープンソースで公開しました。どんどんLLMの開発が進んでいますね。

令和コソコソ噂話: Attention/Transformer 開発者の話
Weights & BiasesのPodcastで、Weights & Biases CEOのLukasとTransformerの元論文”Attention is All You Need”のauthorの一人であるAidan Gomezの対談が面白いです(Aidan Gomez – Scaling LLMs and Accelerating Adoption)。下記、Podcastの一節です(文字起こしのため、ちょっと英語は雑です)。この後の会話も含めて意訳すると”Transformerは複雑と言われるけれども、LSTMsやRNNsなどの系譜を考えれば、発想はattractiveであるものの、シンプルな拡張であると考えている。一方、今までのやり方と反したことは、皆が巨大なモデルを最初から作りたがらない中、思い切って巨大なモデルを作ってみたこと。Transformerは巨大モデルの計算を可能にするStructureであり、これが功を奏した”と言うのが彼のコメントです。「Transformerなんて誰が考えたんだよ。天才かよ」と考えていた私にとって、何が彼らにとって過去の知見に基づいたことなのか/何が斬新なことだったのかというポイントが私としては面白かったです。
And that model, what they were building ended up being the transformer. So it’s like a architecture, which the purpose was really to come up with a much simpler, more refined, scalable architecture than LSTMs RNNs, which were the category of model deployed itslearning before the transformer. And some people view transformers as extremely complex. I think most of those people aren’t putting it in comparison to LSTMs and what came before, because transformers are really just like an attention block stacked on top of a multi layer perceptron or feed forward layer, and then a bunch of those stacked on top of each other. And so I think that’s an incredibly simple and yeah, in comparison to what came before a very simple platform to build off of. Obviously, with the benefit of hindsight, the importance of scale is now obvious. But back then I don’t think it was there was like the general rule of thumb, which was the bigger the neural network, the better. But I don’t think people really grasped how far we in the field needed to push that there were still fears of big models were fitting was this big fear. And you don’t want to get too large, because you’re going to start performing worse at the task that you care about. But I think we took a bet that we can take this to a more extreme level and scale this up to not just single digit accelerators or 10s of accelerators, but 1000s of accelerators. And that bet paid off.
Weights & Biases, Podcast, Aidan Gomez – Scaling LLMs and Accelerating Adoption
Token size・Model size・Computational resourceのバランスを理解しながら進める大規模なモデルの構築
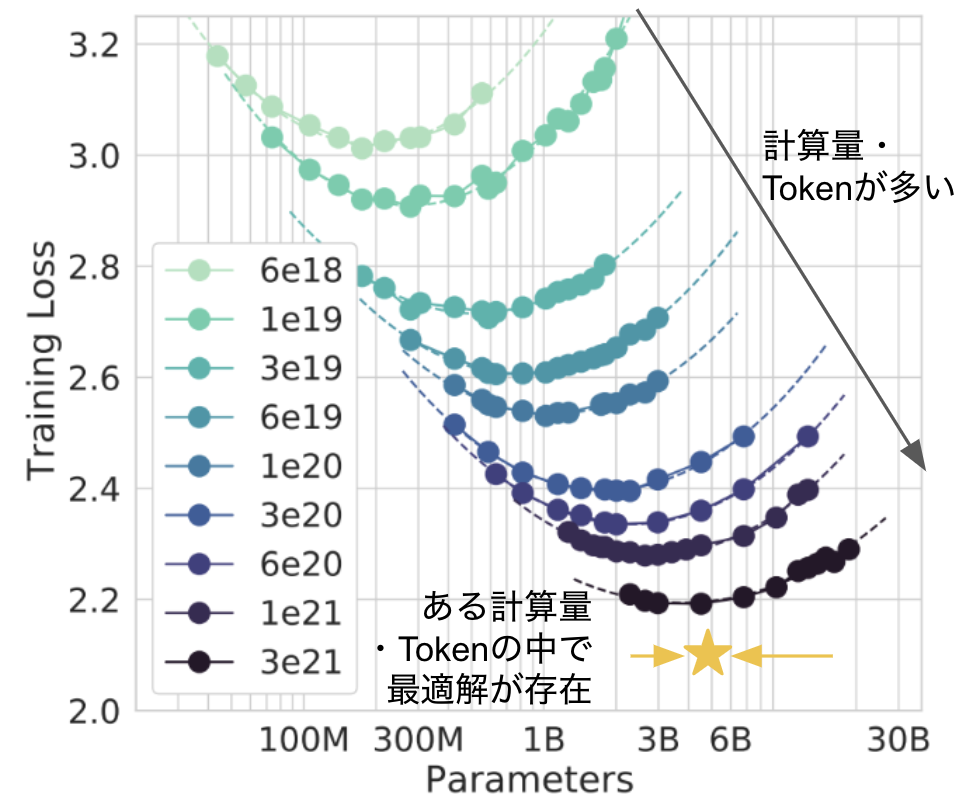
2022年にDeep Mindが、モデルのサイズをただ大きくすることが精度向上に寄与するのではなく、Token size(データ量)・Model size・Computational resource(計算量)のバランスが重要であることを示しました。計算機に物を言わせてToken sizeとModel sizeを大きくしていくことで基本的に精度が向上しますが、Token sizeとModel sizeの最適な関係性の理解も進めながら、モデルの開発が進められたこともLLMの進展に寄与していると考えられます。こうした知見をもとに、今では7800億ものtokenを使って学習し、2.4億ものパラメータを持ったPaLMをGoogleが発表するなど、より大規模なLLMの開発が進められています。
Prompt Engineering
アーキテクチャの工夫に加え、言語モデルに学習させる文章(prompt)の工夫もその進化を進めてきました。対話という新しいインターフェースのもと、入力の工夫・段階的な推論により大幅な精度向上が実現されたという点も、LLMが注目を集める要因であると考えられています。Promptは、機械に与える呪文のようなもので、呪文の投げかけ方により、モデルの精度が変わってきます。Promptはモデルが学習している内容自体を大きく変えることはしないのですが、答えるstyleを提示してあげることで、モデルが持つpotentialを引き出すような手法です。LLMに所望の答えを返してくれるように、人間の方が呪文を工夫する営みは、Siriやアレクサに認識されるように声色を人間が調整していく現象に似ていますね。
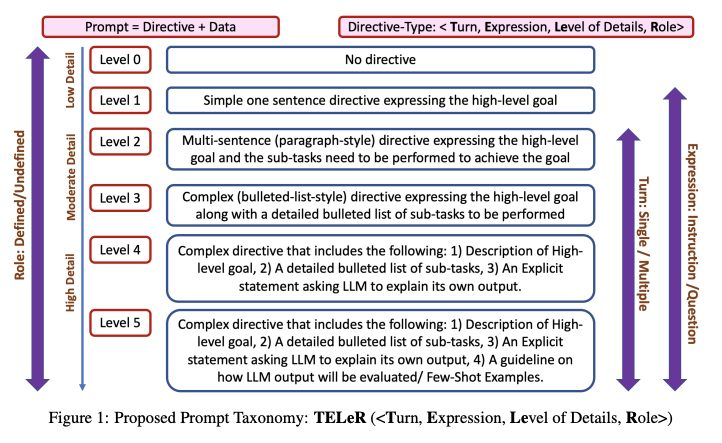
Prompt engineeringのコツについては、Globalでどんどん知識共有が進んでいます。例えば、ChatGPTが答えやすいPromptをChatGPTに作成させている人(Youtube “The ONE ChatGPT Prompt to Rule Them All”)もいます。日本だとHayashi Syunsukeさんが有名です(2023/5時点)。Promptのテンプレート自体をChatGPTに作らせつつ、精度の高い回答をChatGPTに返させるコツなど、どんどん発信されています。うまくいくPromptが次々に解明されつつあり、基本的に細かく適切に指示をするほど回答の質が高いことが知られているのですが、Promptで詳細に記載する内容に応じてレベル分けをする論文も出されるほどです。
その中でもいくつかうまくいくと考えられているPromptのコツを下記で紹介します。
- Few-shot prompting
- Chain-of-Thought Prompting
- Tree-of-Thought Prompting
- Active-Prompt
- Directional Stimulus Prompting
- ReAct Promptin
- Self-Refrection
- Self-Consistency
- Generate Knowledge Prompting
- Automatic Prompt Engineering
- Multimodal CoT Prompting
- Graph Prompting
例えば、Few-shot Learningというのは、問いに対する回答例をいくつか提示し、回答形式や振る舞いを事前に学ばせる手法です。事前に回答の形式を与えることで、回答の精度があがることが知られています。
Chain of Thought(思考の連鎖)は、下記のようにいきなり回答を求めるのではなく、段階的に答えを出すようにするPromptの手法で、これによって精度が上がるということが知られています。Promptの中で”段階的に考えてください”と打つだけでも効果があることが私も経験的に多いです。

Self-Reflectionは、言語モデルが生成した文章を言語モデルに再考させる手法です。生成モデルは、確率的に次にくる単語を予測して出力しているだけになるので、過去に自身が生成した文章を基本的には修正をしません。そのため、一度生成した回答を再度確認させるような指示を与えるだけで回答の質が上がることが知られています。例えば、”to be sure that we have the right answer (筋の良い答えを得ていることを確認してね)”と打ち込むだけでも効果があります。
ReAct(Yao et al., 2022)は、内部情報からの言語的な生成だけでなく、Promptから必要なタスクを認識させ、検索や計算など外部APIを活用した情報を取得し、その情報を付加して回答を返すという考え方になります。高度なPrompt手法ではありますが、LLMを利用したサービス開発に便利で有名なライブラリであるLangChainを活用することでReActを活用したAgentを比較的簡単に構築することができるようになってきています。
上記のように、聞き方一つで回答の質が変わってくることが知られているのですが、ChatGPTなどの対話型言語モデルを日々活用する目的であれば、Promptのコツが形式知化されたテンプレートを使用することをおすすめします。テンプレートは日々いろいろな方が提案していますが、Hayashi SyunsukeさんのNewsPicksの記事の中のテンプレートが簡単で効果の高いテンプレートかと思います。こうした先人の知恵をお借りしつつ、自分のコツを掴んでいってみてください。今後は「ググり力」(検索)に加え、「プロンプティング力」(生成力)が仕事の生産性をあげてくれるかとおもいます。
余談ですが、水曜日のダウンタウンで、街行く人に「いいえ私は蠍座の女」と答えさせるまで帰れないという企画がありました。ロケの最初は、普通に星座を聞いていたのですが、シンプルに「いて座です」という回答しか返ってきませんでした。ロケの後半では、芸人が学習をして、テンプレートを作り始めました。コンビ間で、「あなたはいて座の男ですか?」⇒「いいえ、私は天秤座の男」ですという流れを作った後に、「あなたはいて座の女ですか?」という質問を投げかけることで、「いいえ、私はOO座の女」という返してくれるテンプレートを作ったのです。あとは蠍座の女性を探すだけですね。面白いPrompt Engineeringです。
さらに余談ですが、趣味のワインテイスティングの回答が欲しく(自分で買ったワインにどんな香りがするかなどの正解データが普通ないため)、日本ソムリエ協会のテイスティングフォーマットをChatGPTに教え、半ば冗談で回答を出力させようとしたことがあります。さすがに香りまでは正解しなかったですが、どこでそんな情報を覚えたのか、割と外観などはしっかり当たっていたのが面白かったので、SIGNATEのChatGPTチャレンジに応募したところ、味モーダルへのチャレンジということで特別賞をいただきましたー。(もう少しfew shotsさせていって遊ぼうかと思ったのですが、味に関しての限界はあるだろうと思い、ここまでとしました)

Reinforcement Learning from Human Feedback (RLHF)
実は基盤モデルだけでは、「良いっぽい回答」を得ることが難しく、ChatGPTやBARDなどは、さらにもう一手間行っています。それがReinforcement Learning from Human Feedback (RLHF)です。「人間の受け答えとして自然な感じ」と言うのは定量的な評価ができないため、人が採点をしていく過程を学習プロセスに入れ、よりよい答えがでやすいようにするという発想です。
下記の図は、Andrej Karpathy (Open AI co-founder)が”State of GPT | BRK216HFS“の中でも使用しているChatGPTの開発過程を表した図です。強化学習(Reinforcement Learning)に関連するステップは、後半の2つのステップですが、前から順番に簡単に解説をしていきます。

- Pretraining: ここは上記で確認した基盤モデル(Foundation model)の学習です。
- Supervised Finetuning: 人間が、userとAI assistantのあるべき会話のデータを作成し、それらのデータを使って基盤モデルをファインチューニング(教師あり学習)します。
- Reward Modeling: この段階以降では、回答が「いい感じ」になるようにモデルを微調整していきます。まず、この段階のモデルに対して、いくつかのプロンプトを与え、それぞれのプロントに複数の出力を得ます。複数の出力の中で、人間が「良い」と思う順番をランキングづけし、それらのデータを用いて報酬モデルを学習します。人間の「いい感じ」のメカニズムをここで獲得します。
- Reinforcement Learning: 最後に前段の報酬モデルから得られる報酬(reward)に基づき、Proximal Policy Optimizationというアルゴリズムを用いて、より「いい感じ」の回答が出力されるように強化学習を使ってモデルをfine-tuningしていきます。この最後のステップを入れることで、回答がより「いい感じ」になったとされています。
少し難しいかもしれませんが、人間のフィードバックを強化学習の中に与えながら学習する枠組みが、Reinforcement Learning from Human Feedback (RLHF)です。人間が好ましいと考える結果を反映させる手法として、重要な技術であると考えられています。2023/5時点、RLHFに関するオープンソースがリリースされており、CarperAIのtrlxなどが有名です。
なお、ChatGPTの開発にあたり、強化学習のためのデータを人間が複数の回答の中で「いい感じ」のものを選択をするというやり方が良かったと言われています。「いい感じの文章を作ってください」というより、「いい感じの文章を選択してください」という方が簡単なタスクになりますが、こうしたデータを取得しやすいやり方が功を奏したと言われているわけですね。
学習済みLLMモデルの使用と構築の比較
ここまでTransformerからRLHFまで解説をしましたが、基盤モデルから学習しようとすると、高度な専門性やノウハウ、計算資源が必要であることがわかるかと思います。一から基盤モデルを学習すると、より特定のタスクに特化したモデルを獲得することができますが、全員がその手段を手にいれることができるわけではありません。実際には開発にあたり、ChatGPTやBARD、OpenAIのAPIなど商用LLMを活用するという最も簡単な方法(それでもアウトプットの品質コントロールは難しいですが)や、その間の基盤モデルの一部のパラメータの一部をファインチューニングするという方法もあります。どれが優れているというわけではなく、目的とリソースに合わせた手段を選択していくことになります。それぞれの手法の詳細なPro/Conについては、Weights & BiasesのLLM White Paper“LLMをゼロから トレーニングするためのベストプラクティス”を参考にしてください。すごく良くまとまっています。

LLMに関する議論
LLMによって出された回答には、バイアスがあったり、捏造された(hullucinate)情報が含まれていたりと、活用にはまだまだ課題があり、Andrej Karpathy (Open AI co-founder)も”State of GPT | BRK216HFS“の中で、現状LLMの使用についてはlow-stake applicationで、人間の監修のもと、あくまで助手として扱うように指摘しています。フェアで建設的な批判なら良いのですが、技術的進展がある際には、かならず過剰な反対意見が伴うものですが、そうしたものも含めて代表的な反応や議論を下記に示します。
- 独占状態への危惧: 大規模なモデルの開発には潤沢な予算が必要になるため、一部の大企業の独占状態が生まれる可能性があると懸念されています。スタンフォード大学が出したReport”On the Opportunities and Risks of Foundation Models”(Bommasani et al., 2021)には、基盤モデルの機会とリスクについて解説されています。
- 完全にOpenではない!: ChatGPTは簡単なインターフェースで大規模言語モデルへのAccessibility向上に多大な貢献をしましたが、コード・モデル・学習ログまで全てオープンソースの巨大言語モデル OPT (Zhang et al., 2022)とは対照的に、実は詳細な技術論文が出されていません(公式のblogでInstructGPT(Ouyang et al., 2022)と同じmethodを使用していると言及していますが、詳細な技術論文は出されていません)。GPT-4のversionが発表された際にも、accademicの代物ではなくproductの範疇だという批判もありました。全てをOpenにするとすぐに後追いをされてしまうので完全にOpenにしない理屈は通るかと思いますが、全くaccademicでない・議論なしの技術の進展は止めるべきだという批判の声が大きいことも事実です。
- 開発停止運動: 2023年3月30日、AIの専門家やテック起業家、科学者ら数百人が署名した公開書簡が公開され、OpenAIの言語モデル「GPT-4」より強力なAI技術の開発と試験を一時停止するよう求めました。仕事の自動化(による失業者増加の懸念)だけでなく、偽情報の拡散にも利用される可能性があるという理由からです(REUTERS, 最新版「GPT─4」、調査団体が商業リリース中止をFTCに要請)。(そこにはイーロン・マスクも含まれていましたが、彼はその後AIの新会社「X.AI社」を設立したことが明らかになったため、彼については別の意図があったのかもしれません。)
- 個人情報の取り扱いへの反応: 2023年3月31日、イタリアの個人データ保護当局(GPDP)が、OpenAIが使用する学習データに含まれる数百万人のイタリア人の個人情報の使用を停止するよう、同社に求める緊急暫定措置を講じました。GPDPによると、OpenAIが同社の会話型AI「ChatGPT」で人々の個人情報を使用する法的権利を有していないという決定を受けて、イタリア国内からのChatGPTへのアクセスを停止し、調査を進めている当局に回答を提供する予定にまで発展しています(WIRED AIの学習データに含まれる個人情報が、ChatGPTにとって“大問題”になる)。
- 第一人者の行動: 2023/5に深層学習(LLM)の第一人者であり、AIの父(ゴットファーザー)と呼ばれるジェフリー・ヒントン氏が、Googleを退社していたことを米メディア「The New York Times」に明かしました。彼の言動は、単純に反対するという運動と質が異なるかと思っています。実際同士は、自身のtweetの中で、Googleを批判して辞めるわけではなく、Googleを超えてAIの危険性について述べることができるように退社をしたと述べていますが、広い目線での冷静な彼の意見に、今後注目をしていきたいと思います。
おわりに
本記事では、2021年以降のLLMの概要を紹介しました。特に対話形式のLLMは過熱ぶりがすごいですが、LLMの本質的な技術的進展は確実にあり、例えばヘルスケアの分野ではアミノ酸配列や遺伝子配列の解析にTransformerが用いられ(アミノ酸の配列や遺伝子の配列 = 文字)、薬の開発などに役立てられています。このあたりのoverviewは、Large Language Models in Molecular Biologyが非常にわかりやすいです。今回はLLMの概要をまとめましたが、個人的にはLLMのこうした領域の活用に関心をもっていますので、このあたりはまたblogを書きたいと思っています。また、概要の解説だけではなく、手を動かした結果をblogにまとめていこうと思います。
Reference
細かい文献はリンクを貼っていますが、今回の記事作成にあたり、特に参考になった情報をリストアップします。
- Weights & BiasesのLLM White Paper “LLMをゼロから トレーニングするためのベストプラクティス“。LLM開発の実践がよくまとまったWhite Paperです。
- Andrej Karpathy (Open AI co-founder)の講演”State of GPT | BRK216HFS“
- State of AI : 萩原 正人さんが運営をされているLLMの論文を丁寧にまとめられた記事です。購読にはお金がかかりますが、非常に質の高い情報を発信されています。残念ながら2023/3/31に正式終了するアナウンスがありましたが、2023/4時点では、過去の記事も読めるようになっております。
- O’REILLYの”機械学習エンジニアのためのTransformer”
- Yannic Kilcher氏のYoutube: テンポよくDLに関するわかりやすい解説をしています。様々なレベル感の動画があり、概要レベルから詳細な内容までcatch upすることができます。
